Lock The Services, part I
08 Jun 2019The task is to sync data both to application’s database and ElasticSearch Cache. Both clients sets value to database first then to ES.
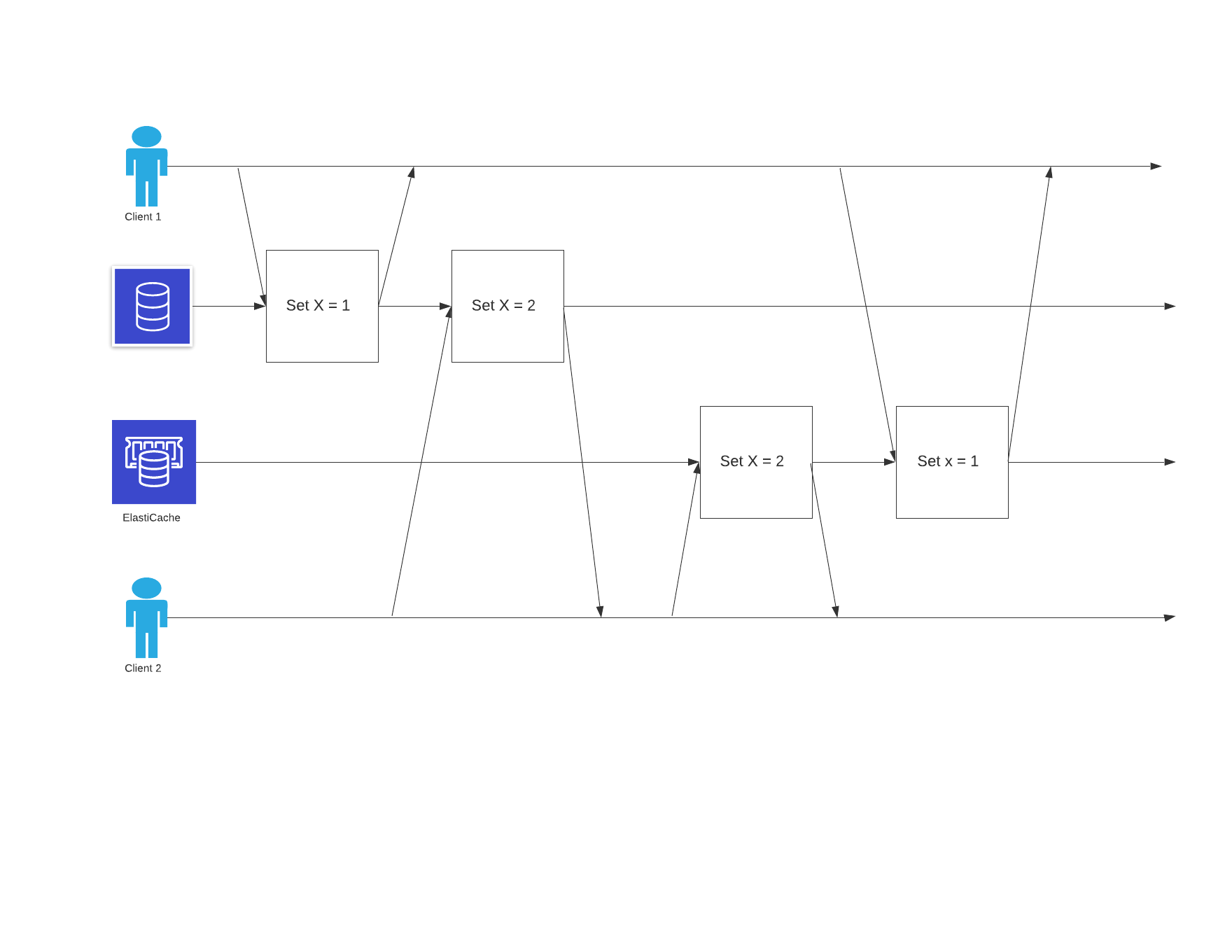
The end result here is that database’s final value is 2 and ES final value is 1. The end result should be the same in both services and both storages.
First the set X = 1 from client 1 is processed by the database but setting the same value to ES is delayed due to versus reasons. Meanwhile setting the X = 2 from client 2 has gone through both database and ES. The reason why client 1’s setting x = 1 was delayed can be because that process took longer than the client 2’s process. Also setting the value to DB and to ES can be two different jobs to be run with message broker so the second job took some more time due to overloading the queue.
We can never be sure that the transactions will run in the right order if we process them in parallelism and we don’t keep track of their ordering of processing. The solution here would be to run the jobs for syncing to ES after success of the first job for both client 1 and client 2. Assuming that sync to db and sync to ES are two processes/jobs but job2 is run from inside the job1 on success. That way job2 for client 1 is run on success of job1 for client 1. Jobs for syncing from client 1 and client 2 are sent to the message broker so ordering of their runtime is established hence won’t happen that the job 1 from client 2 runs before job1 for client 1. This way we ensure linearizability.
However, consider this: We know that job1 for client 2 is run after job1 for client 1 but we can’t make sure that job2 for client 1 is run before job2 for client 2. As we now know that job1 of client 2 runs after job1 of client 1 we can do the same for jobs 2s of both clients. So, running job1 of client 2 after job1 of client 1 and running job2 of client 2 after job2 of client 1.
Another point is that the job2 of any clients or any job actually takes the last data of the record that needs to be updated in any system either database or cache, so a job will get the last state of that record from database and systems will always will reflect last data. Concurrent updates in database lock the row/table (InnoDB/MyIsam) in database that guarantees that data is updated in the right order. Transferring and running the jobs with stale data without fetching the last updated one can be dangerous and is only allowed in scenarios that are independent and relate on systems immutable. Figuring out if the job can run with past input in future event should be allowed only if that historical data needs to be matched/purged.
So this case is tricky in a sense that jobs 2s of both clients should query the last data from database first than update ES. It can not happen that job2 of client 1 updates old data if it runs before job2 of client 2 if both of them query the last state from database, which is how the normal scenario will play out when all systems are running flawlessly. If ES stalls or is down for some reason and both job 2s fail than both of them run again with same input data that they first query so at that point it doesn’t matter which is run first both will sync the same data.
Also possible would be to dispatch the jobs on the same queue in the right order so they are picked up in the right order, if sent on different queues they might be processed in different order which if they sync same data is not a problem but if they sync time-related data when they were run than it is a problem and better be run in the same queue if they sync time-related data. So, running both of the job 2s on the same queue, making sure that consumers take data in right order with should be guaranteed by the message broker like kafka even though there might be more partitions on that queue/topic. The choose of message broker might be related to this issue as well so jobs are not processed in different order than they were dispatched. At that point when jobs hit the ES or the last service (can also be a app with DB), that service also does its fair share of locking so data is updated in the right order on that side as well.